
以前書いた以下の記事
ここからもっと性能を上げたく、いろいろググっているとどうやらRTX3080 10GBで32Bを動かしている方がいらっしゃる様子。
前の検証結果ではVRAMは常にカツカツで余裕はなさそうな状態でした。
そんなん動くんか!と思いつつも動くのであればそれに越したことはないので試してみることに。。。
→次回で書こうと思っている内容ですが、結論としては確かに下がるけどCPU側のRAMも使ってくれて処理していました。
VRAMに収まる分しか動かないと思っていたので大発見!
最近はAIエージェント?とかいうものが流行っているのもあっていろいろチャレンジしているのですがAPI費用が馬鹿にできないのでローカルLLM流行ってくれええええ!
やること
Ollamaをサーバーとして動かす場合、githubを調べているとどうやら環境変数に書き込むことで設定をいろいろ変更できるらしい。
https://github.com/ollama/ollama/blob/main/docs/faq.md#how-do-i-configure-ollama-server
※ちなみにこのFAQに外部に情報を送らない旨が書かれているっぽい(英語スキル自信なしw)
今回はVRAM使用量に影響を及ぼしそうなものを入れていきます。
OLLAMA_KV_CACHE_TYPE
OLLAMA_FLASH_ATTENTIONの二つが効果があるらしく
上のKV_CACHEというのはよくわかりませんでしたがパラメータは量子化に関する値を入れればよいとのこと。これがVRAMの削減にめっちゃ効くらしい。
FLASH_ATTENTIONはStable Diffusionなどでも見ますがあまりよくわかっていませんw
これもVRAM使用量を減らしてくれるものです。FAQページにもありましたが 1 にするだけで有効化されるようです。
というわけでネット上のサンプルをいろいろ見て以下のような設定にしました。
OLLAMA_KV_CACHE_TYPE = "q8_0"
OLLAMA_FLASH_ATTENTION = 1q4_0とかにすると軽くなるようですが回答精度が落ちるとかなんとかでq8がちょうどよいようです。
設定がONの時
前回同様 Continue と利用しています。

今回の設定がOFFの時
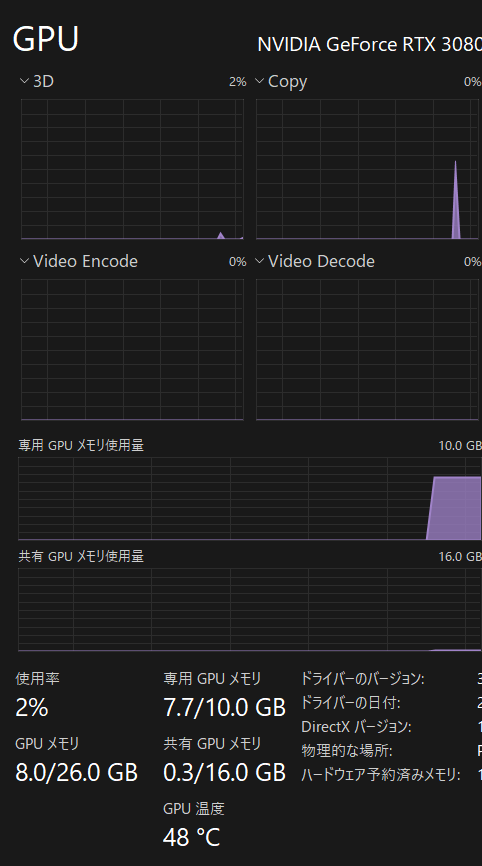
確かに1GBほど減っています!
成果としては7Bと1.5B両方の読み込み時で1GBほど減るようでした。
32BとClineも試しているのですがそれは次回!