
M5Stack LLM界隈でちらちら見ていた qwen って名前のLLM。なんでも日本語でもやり取りができるとか?
英語の語学力が残念な私にとって日本語でやり取りできるLLMめちゃ大事です。
たまたま、Ollamaのモデル一覧を見ているとqwen2.5-coderたるものがあることを発見しました。
VSCodeにCopilot系のものを入れたいと思っていたところにこれが出てきたので試しに構築してみることに。コード用のモデルってどれがいいかわかんないけど0.5bとかあるしお手軽かなって思って入れてみました。
ちなみにOllamaに入っている別のモデルを指定すればそれも使えます。
このモデルは3Bを除いてApache 2.0だそうです。
https://ollama.com/library/qwen2.5-coder
3B以外で手元の環境で動きそうなのが7Bか1.5B。RTX3080搭載環境なのでとりあえず7Bにしました。
とりあえずモデルダウンロード&テスト
ollama run qwen2.5-coder:7b終わったらvscodeにContinueをインストールして画面右下のContinueボタンをクリックします。
Configure Autocomplete Optionsとあるのでそこをクリックします。
表示されたテキストファイルを以下のように編集して保存します。
{
"models": [
{
"title": "qwen2.5-coder",
"provider": "ollama",
"model": "qwen2.5-coder:7b"
}
],
"tabAutocompleteModel": {
"title": "qwen2.5-coder",
"provider": "ollama",
"model": "qwen2.5-coder:7b"
},*このファイルの編集については以下も参照したほうが確実かもしれません。
https://docs.continue.dev/customize/model-providers/ollama
これでVSCodeからチャットを入力すると。。。
これだけで応答が返ってきます!
デメリットとしては7BだとVRAMがかつかつな点。。。
このパソコン組んだ時はこんなにVRAM使うことになるとか想定してなかたですw
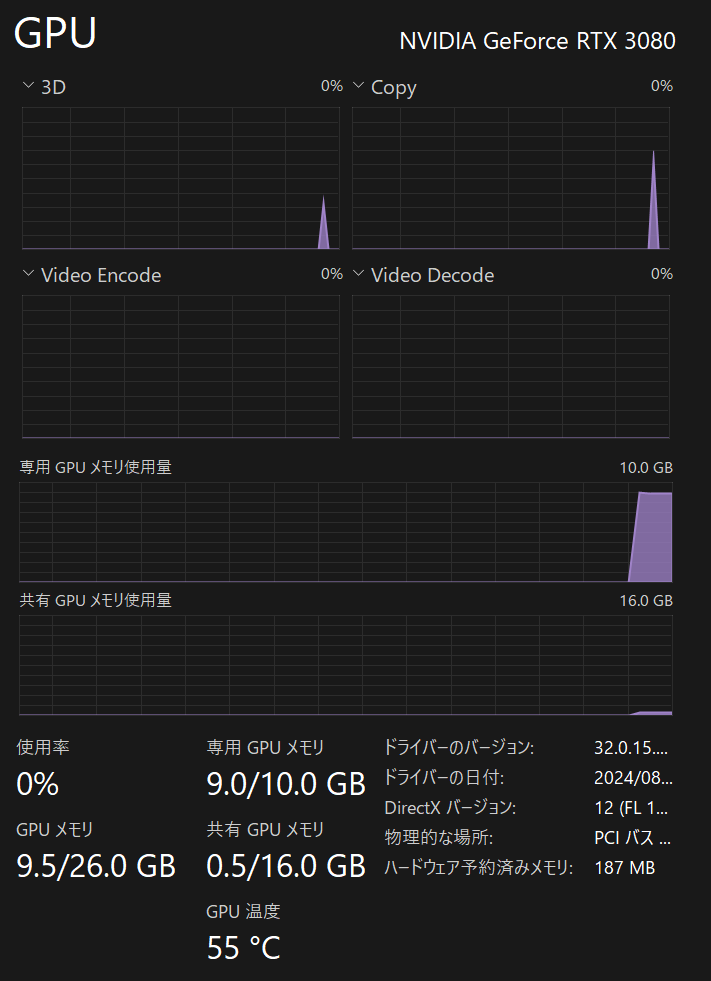
いろいろ試していて。。。
オートコンプリートのモデルは0.5bでも十分かもしれません。
7bと0.5b両方を読み込むとGPUのVRAMが9.7GBに達するためちょっとしんどいですね。。。(´;ω;`)