Redditをのぞいていると、CPUの消費電力を落とすことでGPUの周波数が上がってFPSが上がるとかって書き込みを見つけたので個人的に安全そうな手順を考えてみました。
CPU側のTDP枠を落とすことでGPU側の周波数があげられるということでしょうか?
この場合、ゲームによってはCPU性能が必要な場合もあると思うのでタイトル次第ですが、基本的にはGPU性能に依存するゲームが多いように思うので確かに効果がありそうです。
なお、CPU依存のゲームは逆に性能が低下する可能性があるので注意すること。
故障してほしくないのでUEFIの非表示設定変更やサードパーティのアプリケーションは無しでWindowsの標準機能で頑張ります。
OSならリカバリーすればなんとかなるはず?w
ちなみに他社の ポータブルゲーミングPC でも同様の事象はあるかもしれません。
TurboBoost (ターボブースト) 無効化
まずは手順から。
「プロセッサパフォーマンスの向上モード」を表示するための設定をレジストリから行います。※レジストリをいじるのでリカバリーディスクは必ず事前に作成しておいてください!!!
以下のPowershellコマンドを管理者権限で実行することで表示することができます。
Set-ItemProperty -Path "HKLM:\SYSTEM\CurrentControlSet\Control\Power\PowerSettings\54533251-82be-4824-96c1-47b60b740d00\be337238-0d82-4146-a960-4f3749d470c7" -Name "Attributes" -Value 2 -Type DWord
でコントロールパネルを開いて
コントロール パネル\ハードウェアとサウンド\電源オプションを開きます。
その後、電源プランの作成をクリックしてターボブーストが無効になっていることがわかるプラン名をつけて次へと作成をクリックします。
作成されたプランの右側にある「プラン設定の編集」をクリックして詳細な電源設定の変更をクリックします。
その後、プロセッサパフォーマンスの向上モードを開いてバッテリー駆動と電源に接続をともに無効に変更します。
参考:https://learn.microsoft.com/ja-jp/windows-hardware/customize/power-settings/options-for-perf-state-engine-perfboostmode
結果
普段は3Ghzあたりをウロウロしていますが、ゲームをしているときは3.8Ghzくらいまで行きます。
TurboBoostを無効化することで2Ghzくらいにまで落ちます。
FPSが安定しました。(特に画面が激しく動いているシーン)
これが
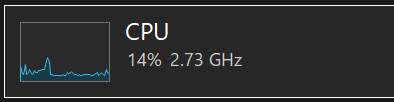
↓
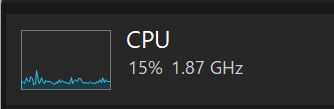
こうなりました。ちなみに、ターボブーストオフでも2Ghzを超えることはあります。
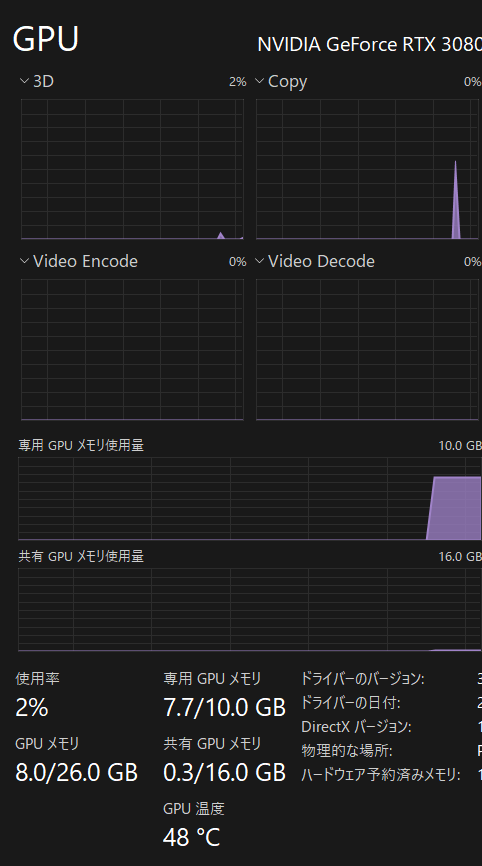
ゲーム中(Apex Legends)のGPU周波数の変化について
TurboBoost無効化状態だとGPU-Z調べで
2250Mhz
まで上がります。

設定前だと
500Mhz – 1700Mhz
※瞬間的に2000Mhzくらいまで行くこともあります。
なので少なくとも500Mhzは高いクロックで動作できるようです。
これは期待できそう
APEX Legends実行時のFPSについては
2560 x 1440 のウインドウ表示で
と若干上がっています。
感想
TurboBoostオフにするだけで十分かも
Webブラウジングとか動画とか軽いゲームなら、Core Ultra 7 155Hは2Ghzまでクロックを落としても快適なのでバッテリーもちとファンの騒音を考えるとポータブルゲーミングPCとしてはオフのままでいい気がしました。